
SANKEN
The University of Osaka
大阪大学
産業科学研究所

LAST UPDATE 2017/02/26
-
研究者氏名
Researcher Name武田龍 Ryu TAKEDA
准教授 Associate Professor -
所属
Affiliation大阪大学 産業科学研究所
知識科学分野
SANKEN, The University of Osaka
Department of Knowledge Science -
研究キーワード
Research Keywords音響信号処理
音声認識
音声対話
Acoustic signal processing
Automatic speech recognition
Spoken dialogue
- 研究テーマ
Research Subject -
音声対話を通じた音声認識用音響・言語モデルの自動高精度化
Automatic improvement of acoustic and language models for automatic speech recognition through spoken dialogues
研究の背景 Background of the Research
近年,音声を用いた知能システムやロボットの研究開発と実用化が進み、社会にも浸透してきています。例えば,NaoやPepperといったロボットは,音声認識や感情認識の機能を備えており,人間とも音声対話が可能です。それに伴い,インタフェースとしての音声の重要性と必要性,社会からの期待が一層増加すると予想されます。
Research and development of intelligent systems and robots have recently advanced, and they start appearing in our society. For example, humanoid robots such as Nao and Pepper can recognize human speech and emotions, and thus they can interact with us using speech. The importance, necessity, and societal expectation of speech as an interface will increase according to such a rapid development of robots.
研究の目標 Research Objective
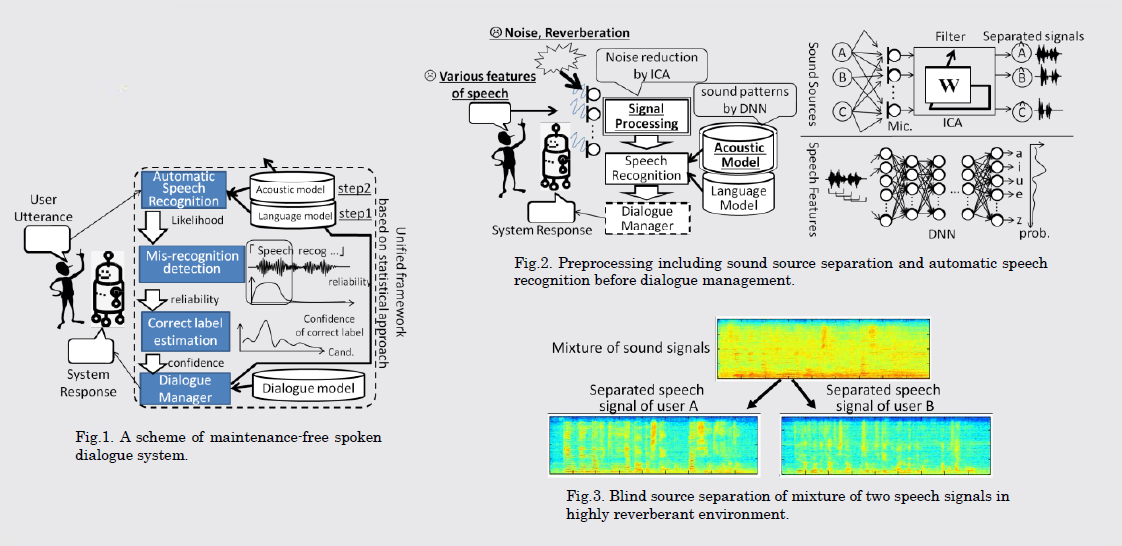
人間と音声対話が可能な知能システムを運用するには,様々な人の声や変化していく言葉を常に正しく認識できる必要があります。これは通常、誤認識した発話を専門家がコストをかけてログから事後的に特定し、音声認識用の音響モデル、言語モデルを更新することで実現しています.これに対して、本研究では音声認識の各モデルに関してメンテナンスフリーの音声対話システムの実現を目的としています。また、ロボットへの実装に必要な音響信号処理・音声認識の各技術も研究を行います。
The operation of intelligent system that can talk with us requires recognizing a variety of human speech signals and varying words correctly at all times. The maintenance of such systems is usually performed by updating acoustic and language models of automatic speech recognition (ASR) after system developers detect misrecognized utterances from the system logs. The purpose of our research is to realize a maintenance-free spoken dialogue system regarding the ASR models. We also study techniques of audio signal processing and ASR required when implementing spoken dialogue robots.
研究図Figures
論文発表 / Publications
Ryu Takeda, et al., “Boundary Contraction Training for Acoustic Models based on Discrete Deep Neural Networks,” Proceedings of Interspeech, pp.1063-1067, 2014
Ryu Takeda, et al., “Efficient Blind Dereverberation and Echo Cancellation based on Independent Component Analysis for Actual Acoustic Signals,” Neural Computation, Vol.24, Issue 1, pp.234-272, 2012
研究者連絡先 / HP
- rtakeda
 sanken.osaka-u.ac.jp
sanken.osaka-u.ac.jp - http://www.ei.sanken.osaka-u.ac.jp/